How to use the COVARIANCE.P function

What is the COVARIANCE.P function?
The COVARIANCE.P function calculates the covariance in two different data sets.
Table of Contents
1. Introduction
What is covariance?
Covariance describes if two variables are connected meaning they rise together or if one decreases as the other increases. In other words, covariance measures how two random variables or datasets vary together.
Covariance is the average of the products of deviations for each pair in two different datasets. The covariance is positive if greater values in the first data set correspond to greater values in the second data set. The covariance is negative if greater values in the first data set correspond to smaller values in the second data set.
What is the average of the products of deviations for each pair in two different datasets?
The covariance between two datasets is computed by taking each data point, finding its deviation from its respective dataset mean by subtracting the mean, multiplying the two datasets' deviations together for each pair, and averaging these cross-products of deviations.
What is deviation?
In statistics, deviation is a measure of how far each value in a data set lies from the mean (the average of all values). A high deviation means that the values are spread out widely, while a low deviation means that they are clustered closely around the mean.
What is the mean?
It is also known as the average. It is calculated by adding up all the values in the data set and dividing by the number of values.
For example, if you have a data set of 5, 7, 9, 11, and 13, the mean is (5 + 7 + 9 + 11 + 13) / 5 = 9.
How to interpret covariance?

A positive covariance means that the variables tend to increase or decrease together indicating a positive linear relationship. The top left chart above shows variables with a positive covariance.
A negative covariance means that the variables tend to move in opposite directions indicating a negative linear relationship. The bottom left chart above shows variables with a negative covariance.
A zero covariance means that the variables are independent and have no linear relationship. The top and bottom right charts shows data with no linear relationship, the covariance is close to zero.
However, covariance is not a standardized measure and it depends on the scale and units of the variables. It is not easy to compare the covariances of different pairs of variables or interpret the strength of the relationship. A more common and useful measure of linear relationship is the correlation coefficient, which is the normalized version of covariance.
How to calculate normalized version of covariance?
To calculate the normalized version of covariance, which is also known as the correlation coefficient, you need to divide the covariance by the product of the standard deviations of the two variables. The standard deviation is a measure of how much the values in a data set deviate from the mean.

The correlation coefficient tells you also how much related the pairs are, this is not the case with the measure of covariance. The image above shows two charts, the data set in the right chart is identical to the left chart except they are ten times larger. Covariance is much larger for the right chart.
See the CORREL function for more.
2. Syntax
COVARIANCE.P(array1, array2)
3. Arguments
| array1 | Required. The first data set. |
| array2 | Required. The second data set. |
4. Example 1
You have data on the monthly closing prices of Microsoft and the monthly values of a market index (S&P 500) over a period of three years. Calculate the population covariance between the stock prices and the market index to determine if there is a relationship between the two?
Formula in cell C18:
If the S&P500 data represents index values and the Microsoft data represents stock prices, the covariance value of 18346 would be in the units of
index value × stock price.
It's essential to understand the units of the input data to interpret the covariance value correctly.
The sign of the covariance value indicates the direction of the relationship between the two variables. A positive covariance value (18346 in this case) suggests that S&P500 and Microsoft tend to move in the same direction. When S&P500 increases (decreases), Microsoft's stock price also tends to increase (decrease).
The size of the covariance value alone is not very helpful in analyzing the strength of the relationship. A larger covariance value doesn't necessarily imply a stronger relationship. It could be influenced by the units or scales of the input data.
Use the CORREL function to analyze how strong the correlation between the S&P500 and Microsoft is. The correlation coefficient is calculated like this:
COVARIANCE.P(X, Y) / (STDEV.P(X) * STDEV.P(Y)) however, the CORREL function does this for you.
5. Function not working
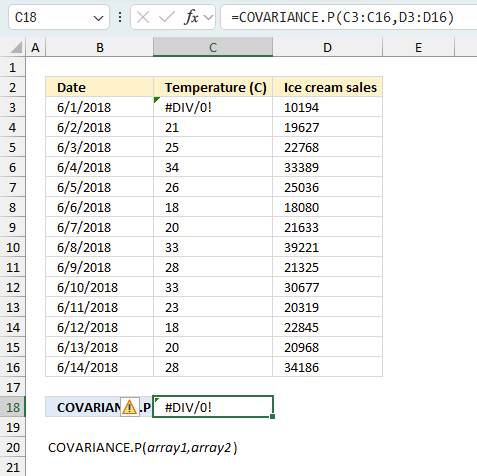
Text, logical or empty values are ignored, however, 0 (zeros) are included.
The COVARIANCE.P function returns
- #N/A error value if the number of data points in array1 and array2 is not equal.
- #DIV/0! error value if either array1 or array2 is empty.
- #VALUE! error if you use a non-numeric input value.
- #NAME? error if you misspell the function name.
- propagates errors, meaning that if the input contains an error (e.g., #VALUE!, #REF!), the function will return the same error.
5.1 Troubleshooting the error value
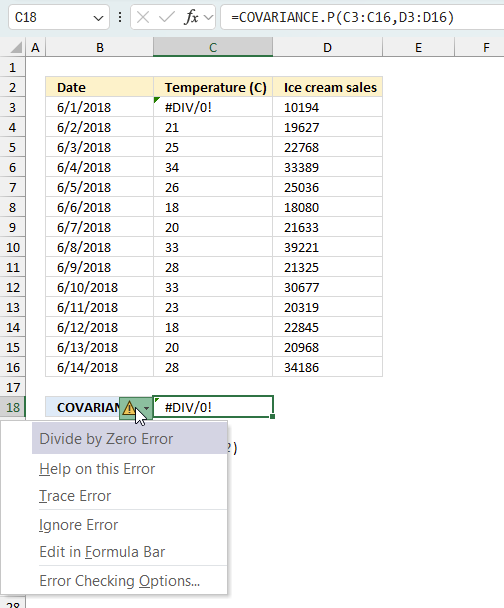
When you encounter an error value in a cell a warning symbol appears, displayed in the image above. Press with mouse on it to see a pop-up menu that lets you get more information about the error.
- The first line describes the error if you press with left mouse button on it.
- The second line opens a pane that explains the error in greater detail.
- The third line takes you to the "Evaluate Formula" tool, a dialog box appears allowing you to examine the formula in greater detail.
- This line lets you ignore the error value meaning the warning icon disappears, however, the error is still in the cell.
- The fifth line lets you edit the formula in the Formula bar.
- The sixth line opens the Excel settings so you can adjust the Error Checking Options.
Here are a few of the most common Excel errors you may encounter.
#NULL error - This error occurs most often if you by mistake use a space character in a formula where it shouldn't be. Excel interprets a space character as an intersection operator. If the ranges don't intersect an #NULL error is returned. The #NULL! error occurs when a formula attempts to calculate the intersection of two ranges that do not actually intersect. This can happen when the wrong range operator is used in the formula, or when the intersection operator (represented by a space character) is used between two ranges that do not overlap. To fix this error double check that the ranges referenced in the formula that use the intersection operator actually have cells in common.
#SPILL error - The #SPILL! error occurs only in version Excel 365 and is caused by a dynamic array being to large, meaning there are cells below and/or to the right that are not empty. This prevents the dynamic array formula expanding into new empty cells.
#DIV/0 error - This error happens if you try to divide a number by 0 (zero) or a value that equates to zero which is not possible mathematically.
#VALUE error - The #VALUE error occurs when a formula has a value that is of the wrong data type. Such as text where a number is expected or when dates are evaluated as text.
#REF error - The #REF error happens when a cell reference is invalid. This can happen if a cell is deleted that is referenced by a formula.
#NAME error - The #NAME error happens if you misspelled a function or a named range.
#NUM error - The #NUM error shows up when you try to use invalid numeric values in formulas, like square root of a negative number.
#N/A error - The #N/A error happens when a value is not available for a formula or found in a given cell range, for example in the VLOOKUP or MATCH functions.
#GETTING_DATA error - The #GETTING_DATA error shows while external sources are loading, this can indicate a delay in fetching the data or that the external source is unavailable right now.
5.2 The formula returns an unexpected value
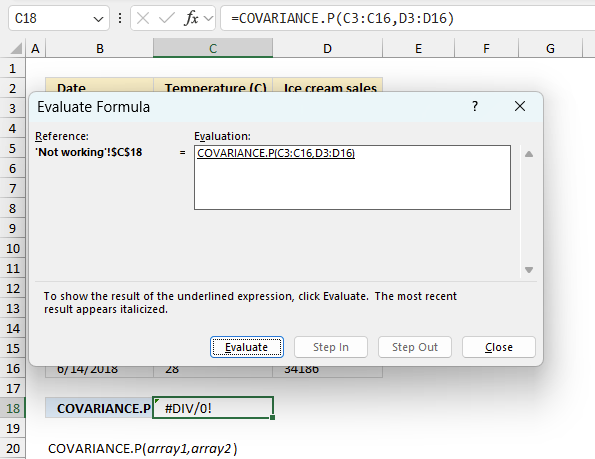
To understand why a formula returns an unexpected value we need to examine the calculations steps in detail. Luckily, Excel has a tool that is really handy in these situations. Here is how to troubleshoot a formula:
- Select the cell containing the formula you want to examine in detail.
- Go to tab “Formulas” on the ribbon.
- Press with left mouse button on "Evaluate Formula" button. A dialog box appears.
The formula appears in a white field inside the dialog box. Underlined expressions are calculations being processed in the next step. The italicized expression is the most recent result. The buttons at the bottom of the dialog box allows you to evaluate the formula in smaller calculations which you control. - Press with left mouse button on the "Evaluate" button located at the bottom of the dialog box to process the underlined expression.
- Repeat pressing the "Evaluate" button until you have seen all calculations step by step. This allows you to examine the formula in greater detail and hopefully find the culprit.
- Press "Close" button to dismiss the dialog box.
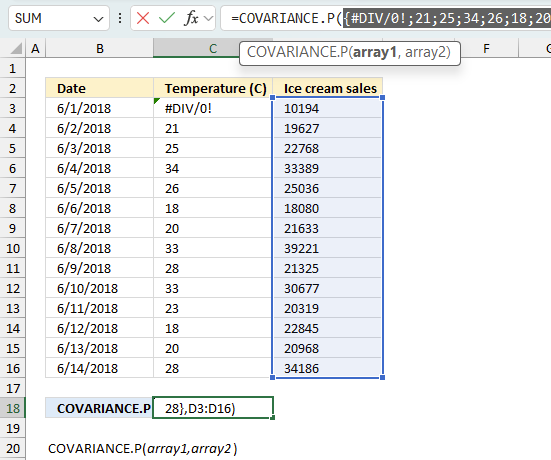
There is also another way to debug formulas using the function key F9. F9 is especially useful if you have a feeling that a specific part of the formula is the issue, this makes it faster than the "Evaluate Formula" tool since you don't need to go through all calculations to find the issue..
- Enter Edit mode: Double-press with left mouse button on the cell or press F2 to enter Edit mode for the formula.
- Select part of the formula: Highlight the specific part of the formula you want to evaluate. You can select and evaluate any part of the formula that could work as a standalone formula.
- Press F9: This will calculate and display the result of just that selected portion.
- Evaluate step-by-step: You can select and evaluate different parts of the formula to see intermediate results.
- Check for errors: This allows you to pinpoint which part of a complex formula may be causing an error.
The image above shows cell reference C3:C16 converted to hard-coded value using the F9 key. The COVARIANCE.P function requires numerical values which is not the case in this example. We have found what is wrong with the formula.
Tips!
- View actual values: Selecting a cell reference and pressing F9 will show the actual values in those cells.
- Exit safely: Press Esc to exit Edit mode without changing the formula. Don't press Enter, as that would replace the formula part with the calculated value.
- Full recalculation: Pressing F9 outside of Edit mode will recalculate all formulas in the workbook.
Remember to be careful not to accidentally overwrite parts of your formula when using F9. Always exit with Esc rather than Enter to preserve the original formula. However, if you make a mistake overwriting the formula it is not the end of the world. You can “undo” the action by pressing keyboard shortcut keys CTRL + z or pressing the “Undo” button
5.3 Other errors
Floating-point arithmetic may give inaccurate results in Excel - Article
Floating-point errors are usually very small, often beyond the 15th decimal place, and in most cases don't affect calculations significantly.
6. How is the function calculated

To calculate the covariance for a population follow these steps:
- Calculate the mean of group of numbers named:
x="Temp"
y="Icecream"
For example:
Mean of X = x̄ is calculated in cell C10
Mean of Y = ȳ is calculated in cell D10 - For each data point xi and yi calculate the deviations from the mean.
Deviation of xi = xi - x̄ are calculated in cells E3:E9
Deviation of yi = yi - ȳ are calculated in cells F3:F9 - Multiply the deviations between each data point pair to get their products.
For each pair: (xi - x̄) * (yi - ȳ) are calculated in cells G3:G9 - Sum all the deviation products.
S = Σ(xi - x̄)(yi - ȳ) calculated in cell G10 - The covariance is the sum of products divided by the number of samples.
The equation for COVARIANCE.P is:
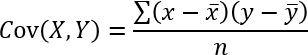
COVARIANCE.P(x,y) = (Σ(xi - x̄)(yi - ȳ))/n
x̄ is the sample means AVERAGE(array1)
ȳ is the sample means AVERAGE(array2)
n is the sample size.
Functions in 'Statistical' category
The COVARIANCE.P function function is one of 73 functions in the 'Statistical' category.
How to comment
How to add a formula to your comment
<code>Insert your formula here.</code>
Convert less than and larger than signs
Use html character entities instead of less than and larger than signs.
< becomes < and > becomes >
How to add VBA code to your comment
[vb 1="vbnet" language=","]
Put your VBA code here.
[/vb]
How to add a picture to your comment:
Upload picture to postimage.org or imgur
Paste image link to your comment.
Contact Oscar
You can contact me through this contact form